
My Co-Learning paper was accepted at RO-MAN 2026
Why I want a robot to remember how a team worked before
Our paper, Improving Human-Robot Teamwork in Urban Search and Rescue Through Episodic Memory of Prior Collaboration, was accepted at RO-MAN 2026. I worked on this together with Emma van Zoelen and Mark Neerincx, in collaboration with TNO and TU Delft. I wrote a structured overview on the project page, and the paper itself is on arXiv.
This project sits inside a research direction I care about a lot: explicit memory for agents. In most of my earlier work I studied memory for a single reinforcement-learning agent. Here I wanted to ask the same question in a team setting. When a robot joins a new collaboration with a person, does it have to start from nothing every time, or can it carry forward something useful it learned from past teamwork?
That framing matters to me because the very beginning of a collaboration is exactly when a team is least coordinated. If a robot could enter a new interaction already holding a good prior memory of how similar situations were solved before, that early stretch might go a lot more smoothly.
What the paper is about
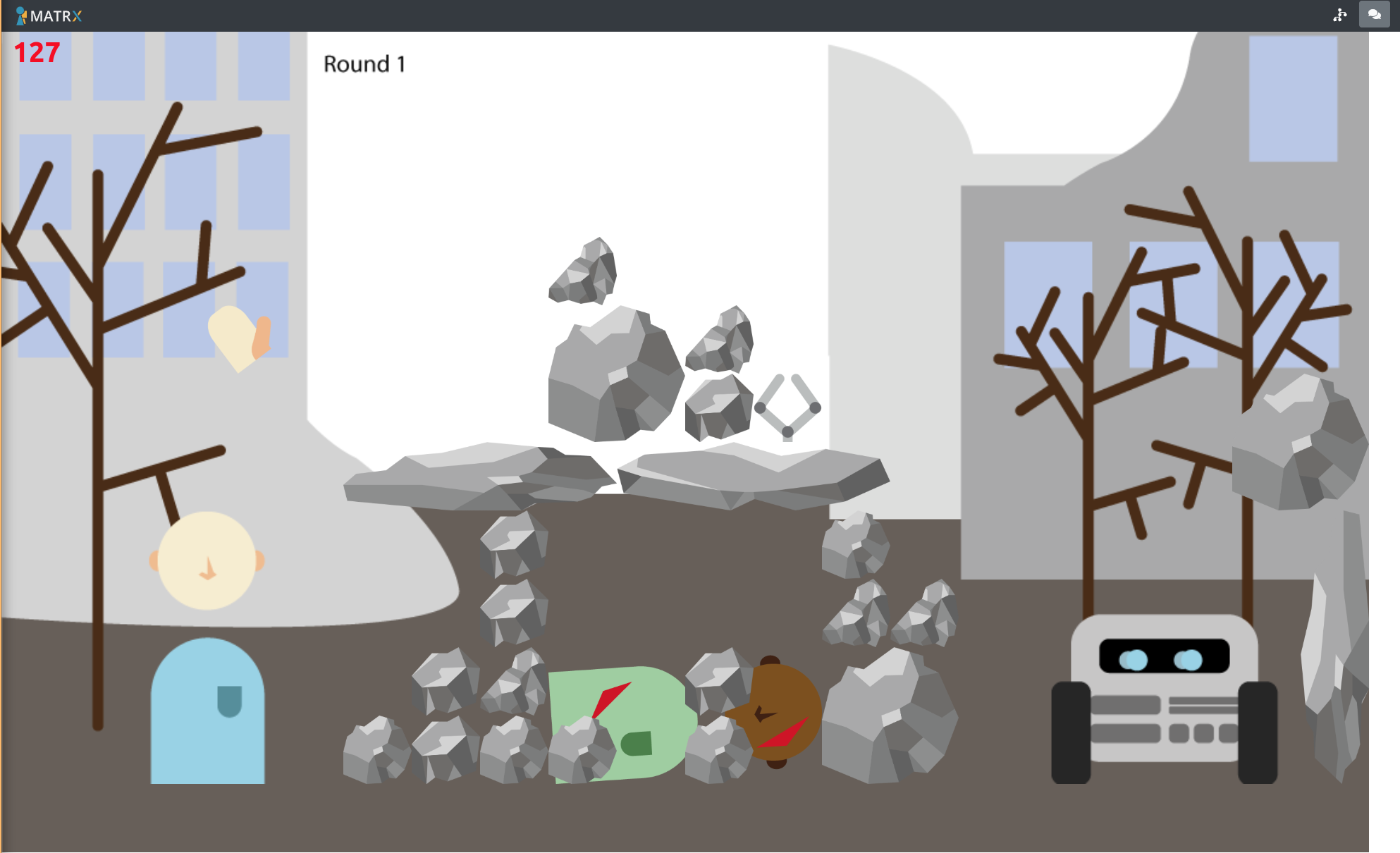
We use the MATRX Urban Search and Rescue environment, where a human and a collaborative robot work together to free a buried victim by clearing rubble. In earlier studies, people could externalize the collaboration patterns (CPs) they discovered during teamwork through a chat and reflection interface.
My starting point is to treat each of those collaboration patterns as an explicit knowledge-graph episodic memory. A CP is not a flat feature vector; it has structure: a situation, an ordered sequence of human and robot actions, and an outcome. So I represent each one as a small knowledge graph that keeps that structure intact.
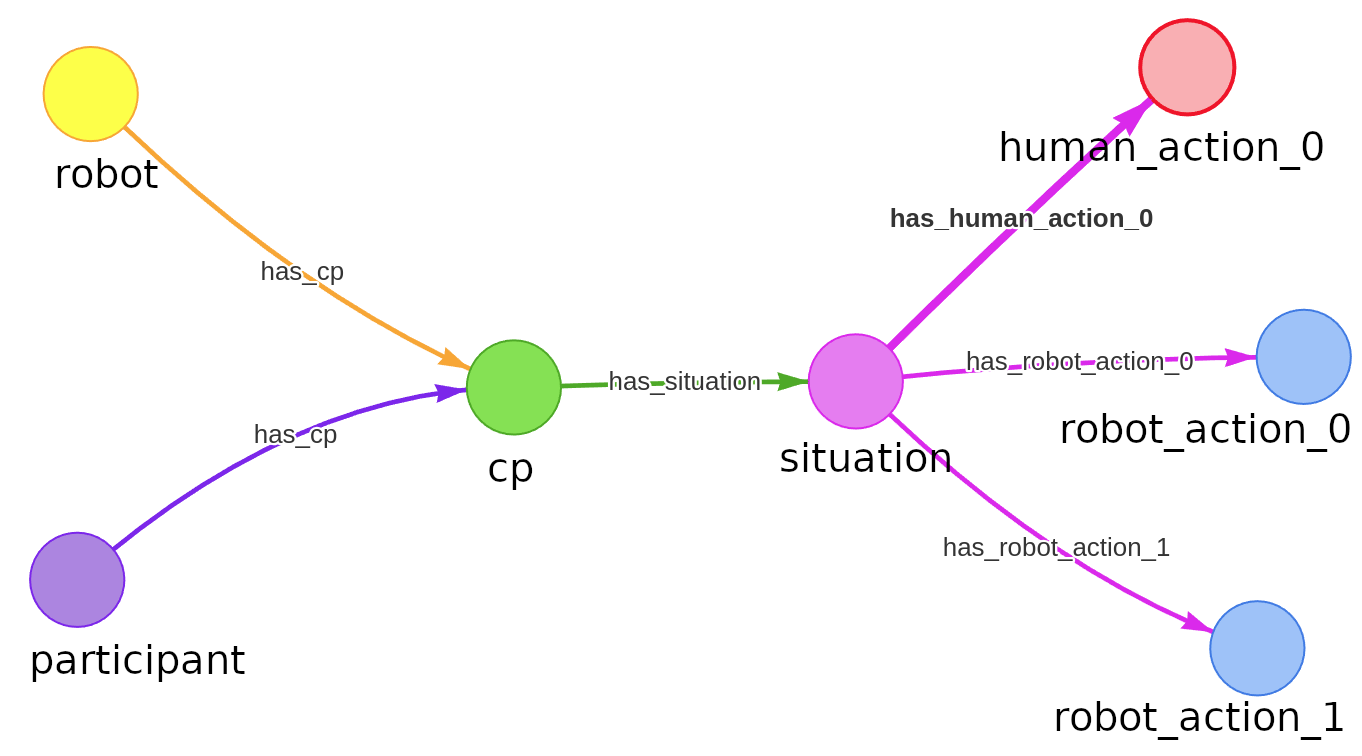
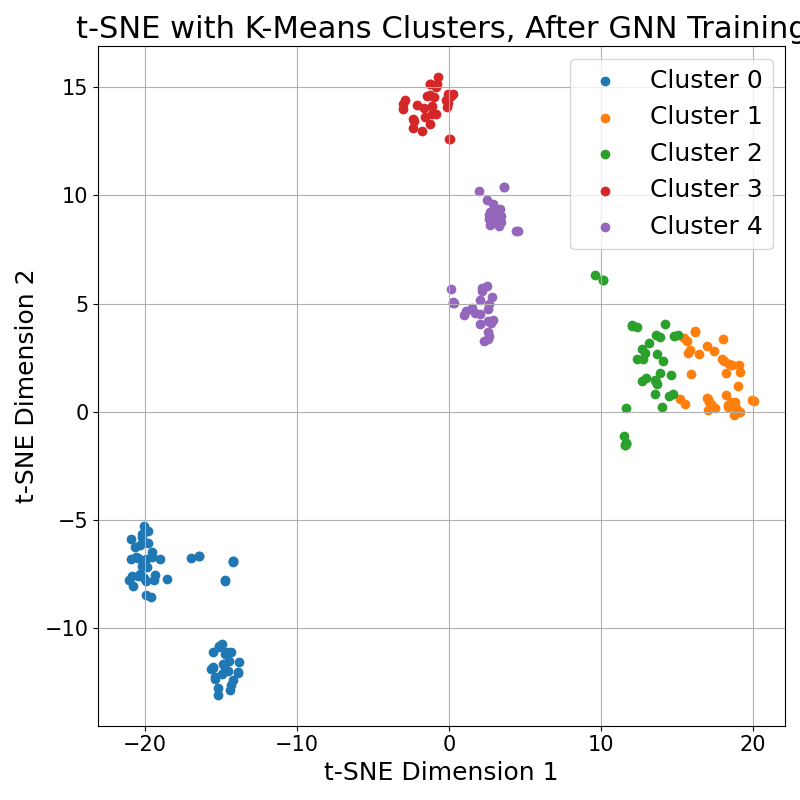
We collected 209 of these CPs and learn representations over them with a Relational Graph Convolutional Network (RGCN), trained with a node-classification objective. An RGCN layer updates each node from its typed neighbors,
where the relation type is the edge label, so the encoder can tell an early action apart from a later one. I then mean-pool the node embeddings into one vector per CP, cluster them with K-means, and pick the CP closest to a cluster center as a representative prior. That single CP is what we preload into the robot before a new episode begins.
The part I want to stress is that the transferred prior stays a readable situation-action structure. It is not an opaque policy update. An operator could look at it, discuss it, or switch it off before it is ever used.
Why I find the result interesting
We then ran a study with 20 participants. Initializing the robot with that one automatically selected prior CP raised rescue success from 25.7% to 41.3% and reduced average task time by 283 seconds. The largest gains showed up in the very first round, before participants had time to adapt to the task, which is exactly where I hoped a useful prior memory would help most.
I also want to be honest about where it did not help. Victim harm went up on average, and performance dropped in the hardest later rounds, where a brown rock changes the local risk of moving debris. The selected CP never referenced that rock, so the mismatch shows up exactly where you would expect. To me that is a feature of the work, not something to hide: because the memory is explicit, the failure is interpretable rather than mysterious.
Why this fits the broader project
This paper feels like a natural extension of the memory line of work I have been building. First I asked whether explicit memory helps an agent. Then I asked whether parts of memory management can be learned. Now I am asking whether a memory of how a team worked together can be carried into a new interaction at all.
I do not think of memory as one monolithic module. I think of it as a set of concrete subproblems, and “what should a robot remember about its past teammates and bring into the next collaboration” is one I had not touched before. It also pushes me past single-agent settings into human-robot teaming, which is where a lot of this eventually has to land.
This is also not a grand new theory of memory transfer. It is one concrete mechanism, in one environment, with clear limitations: a simulation, a small sample, a heuristic single-CP selection, and no random or multi-CP baselines yet. I would rather present it that way and keep the door open for the obvious next steps.
Links
- Project page: Co-Learning
- Paper: arXiv
- GitHub: co-learning