
Sequential Decision-Making with Transformers
Offline RL, Behavior Cloning, and The Magic of Sequence Modeling

Sequential decision-making is a fundamental challenge in machine learning and AI. From planning your next vacation itinerary to training a robot to navigate a warehouse, we often face tasks where a series of actions must be taken to achieve a goal, often with delayed feedback or sparse rewards.
Interestingly, training a large language model (LLM) can be seen as a form of offline sequential decision-making. In this context, the “actions” are the tokens generated by the model, and the “sequences” correspond to coherent sentences or paragraphs. Using Transformers, these models are trained on vast datasets (offline data) without any real-time exploration or direct feedback. Instead, they simply learn to mimic the patterns in the data through behavior cloning, making them incredibly effective at generating high-quality sequences.
In this post, we’ll explore how Transformers can be leveraged for direct sequence learning in an offline setting—whether it’s for LLMs or decision-making tasks—and why behavior cloning can work surprisingly well, even when rewards are sparse or delayed.
The Complexity of Sequential Decision-Making
Sequential decision-making involves making a series of choices over a time horizon . Each action you take can lead to new states, eventually culminating in some terminal outcome. The challenge: the number of possible trajectories can grow exponentially with the time horizon.
Example: Planning a Travel Itinerary
Imagine you are planning a multi-step trip. You start in your hometown () and need to decide your next destination. At each step, you have multiple options, such as visiting a nearby city or staying put. Your goal is to maximize your overall enjoyment (reward) at the end of the trip. However, you only get feedback about how enjoyable your trip was after the trip is complete.
Here’s how this decision-making process might look:
- State (): Your current location, e.g., “Amsterdam.”
- Action (): Options like “Visit Paris,” “Stay in Amsterdam,” or “Go to Berlin.”
- Reward (): Immediate rewards might be unclear or nonexistent until the end of the trip, when you reflect on the overall experience.
If we visualize this as a tree:
- The root node is , your starting location.
- Each branch represents a potential action ().
- Each node is a new state () resulting from that action.
By the time you reach the final depth of the tree (), you could have a massive number of possible paths—making it challenging to determine which sequence of actions will lead to the best reward.
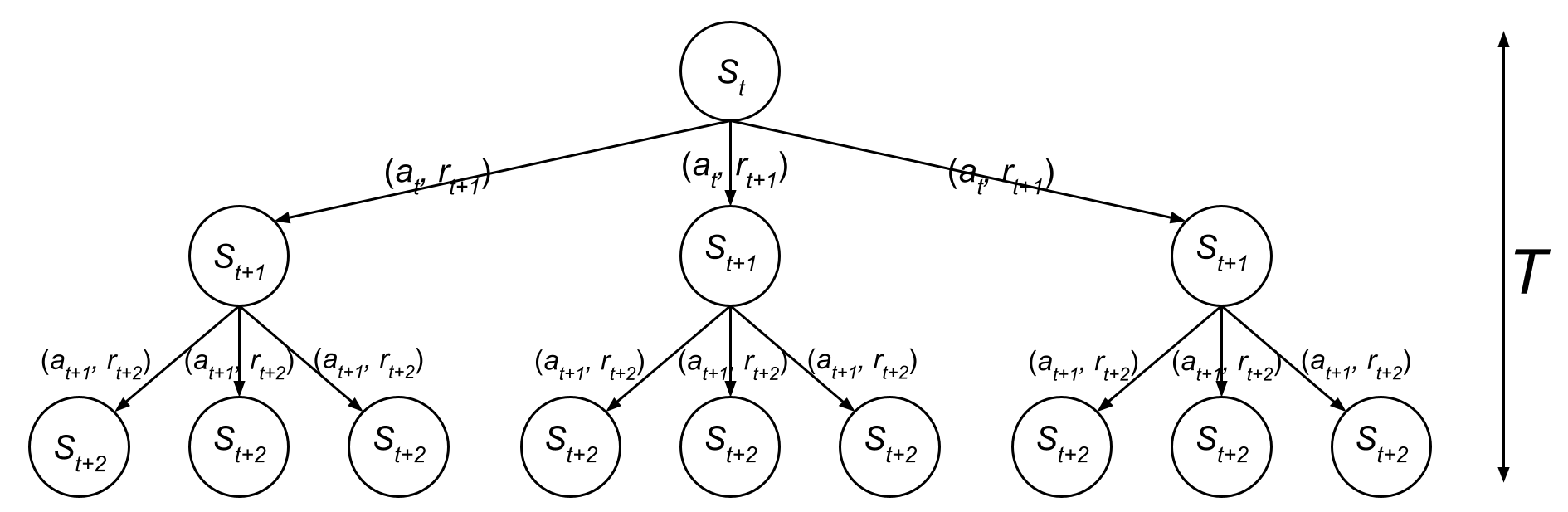 {: .center-image }
{: .center-image }
Delayed Feedback and Exponential Growth
- Delayed Feedback: The enjoyment (reward) of the trip is only realized after it is complete. This makes it hard to know if an intermediate action (e.g., “Visit Paris”) was good or bad until the end.
- Exponential Growth: If there are possible actions at each state, then by time , there are possible trajectories to evaluate.
This example highlights why sequential decision-making is a hard problem, especially when rewards are sparse or delayed.
Sequential Decision-Making with Reinforcement Learning
The goal of reinforcement learning is to solve the sequential decision-making problem by maximizing the expected cumulative discounted rewards:
where:
- : Reward at time step , received after taking action ,
- : Discount factor that prioritizes immediate rewards over future ones, and
- : Horizon of the decision-making problem.
This objective can be tackled using two primary approaches: model-free methods and model-based methods.
Model-Free Methods: A Comprehensive Overview
Model-free reinforcement learning focuses on learning optimal policies or value functions directly from interactions with the environment, without building an explicit model of the environment’s dynamics. This approach is broadly categorized into two main types:
-
Value-Based Methods:
- Q-Learning: Learns the value of taking a specific action in a specific state. The agent learns a Q-function, , which estimates the expected cumulative reward of taking action in state and following the optimal policy thereafter.
- Deep Q-Networks (DQN): Utilizes neural networks to approximate the Q-function, enabling the handling of high-dimensional state spaces.
-
Policy-Based Methods:
- Policy Gradient: Directly parameterizes and optimizes the policy by maximizing the expected cumulative reward. Unlike value-based methods, policy gradients do not require the Bellman equation and can naturally handle continuous action spaces.
- REINFORCE Algorithm: A basic policy gradient method that updates policy parameters in the direction that increases the probability of actions that lead to higher rewards.
-
Actor-Critic Methods:
- Combines value-based and policy-based approaches by having an actor (policy) and a critic (value function). The critic evaluates the action taken by the actor, providing feedback to improve the policy.
- Examples include Advantage Actor-Critic (A2C) and Proximal Policy Optimization (PPO).
Advantages of Model-Free Methods:
- Simplicity: Do not require modeling the environment’s dynamics.
- Flexibility: Can handle a wide range of environments, including those with complex or unknown dynamics.
- Direct Optimization: Policy-based methods can directly optimize the expected reward without intermediate value estimates.
Challenges of Model-Free Methods:
- Sample Inefficiency: Often require a large number of interactions with the environment to learn effective policies.
- Stability and Convergence: Training can be unstable, especially with function approximators like neural networks.
- Exploration: Balancing exploration and exploitation can be difficult, potentially leading to suboptimal policies if not managed properly.
Model-Based Methods: Learning a World Model
In model-based RL, the agent first learns a world model that captures the environment’s dynamics and reward structure. The world model is expressed as a probabilistic function:
where:
- : The probability of transitioning to state and receiving reward given state and action .
Using this world model, the agent can simulate trajectories and evaluate actions, enabling explicit planning to solve the same objective:
By leveraging the learned model, the agent predicts the outcomes of sequences of actions and selects the optimal policy.
Model-Free vs. Model-Based
Both model-free and model-based approaches aim to maximize the same objective: the expected cumulative discounted rewards. The key differences lie in their methodologies and trade-offs:
| Aspect | Model-Free RL | Model-Based RL |
|---|---|---|
| Approach | Directly learn a policy or value function | Learn environment dynamics and rewards |
| Tool | Q-Learning, Policy Gradients, Actor-Critic methods | World model with planning |
| Advantages | Simpler implementation, robust to model inaccuracies | Enables lookahead, can be more sample-efficient |
| Challenges | Sample inefficient, can be unstable during training | Requires accurate model, can be complex to train |
Model-free methods rely on directly optimizing policies or value functions through experience, while model-based methods first build an approximation of the environment to facilitate planning. Both approaches have their strengths and weaknesses, and often hybrid methods that combine elements of both are employed to leverage their respective advantages.
Direct Sequence Learning with Transformers
Instead of iterative value updates (as in model-free RL) or explicit planning (as in model-based RL), we can directly treat the entire sequence
as something to be modeled by a neural network. While this can be done using architectures like RNNs, e.g., LSTMs, the Transformer has become the dominant choice not only because of its powerful attention mechanism, which captures dependencies across all tokens in a sequence regardless of their distance, but also due to its ability to be trained in parallel. Unlike RNNs, which require sequential processing and backpropagation through time in training, Transformers can handle entire sequences simultaneously. This parallelism leads to significantly more efficient training and makes Transformers particularly well-suited for handling long sequences.
Behavior Cloning: A Simpler Approach
For methods like Decision Transformer and Large Language Models (LLMs), we take a simpler approach. Instead of relying on reinforcement learning techniques or reparameterization to optimize a reward objective, these models assume access to large amounts of high-quality offline data. The objective then shifts from reward maximization to maximum likelihood, as in supervised learning. This process is called behavior cloning, where the model learns to imitate the sequences in the dataset.
The training objective for behavior cloning is typically a cross-entropy loss between the one-hot encoded ground truth actions and the predicted action probabilities from the neural network:
where:
- : Ground truth action at time step as a one-hot encoded vector,
- : Predicted probability of action at time step ,
- : Size of the action space.
By minimizing this loss, the model learns to closely match the action distributions in the offline dataset.
Illustration: Learning Only from Offline Data
In reinforcement learning, agents typically explore a wide range of states and actions. In the previous image, all the nodes were white, representing valid states, and all edges represent valid actions that the agent could theoretically explore.
However, in behavior cloning, the agent does not explore the environment. Instead, it learns only from the states and actions available in the offline dataset. The image below highlights this difference, where only the yellow nodes represent states that were included in the training data, and only the edges between them represent actions the model learns to imitate:
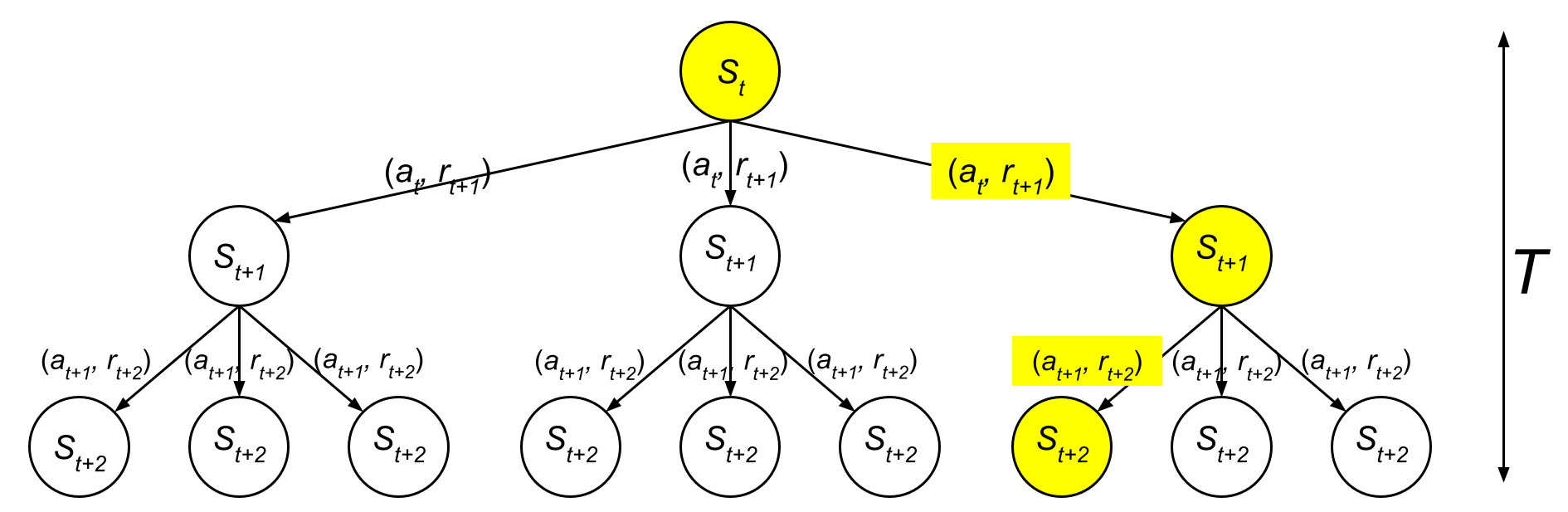 {:
.center-image }
{:
.center-image }
This visual highlights the key limitation of behavior cloning: the agent cannot generalize beyond the trajectories available in the offline data.
Key Points:
- There is no sampling during training.
- The model directly learns from the offline data using teacher forcing, where ground truth actions are provided at every step as input, allowing it to learn to imitate the sequences in the dataset, instead of using the sampled actions.
- The quality of the training data is crucial because the agent can only learn from what it sees.
Why Transformers Are Effective
Transformers excel at learning sequences due to their self-attention mechanism, which allows them to capture dependencies across tokens, no matter how far apart they are. Once trained, these models can be prompted to generate desired sequences:
- Decision Transformer: Adds a goal token at the start of the input to guide the generation of a trajectory that achieves a specific outcome.
- Large Language Models (LLMs): Use massive prompt tuning to condition the model on specific instructions or contexts, enabling it to generate coherent and desired outputs.
For instance:
-
In Decision Transformer, input tokens might look like:
The goal token helps the model generate a trajectory aligned with the desired objective.
-
In LLMs, we can prepend instructions to condition the model’s generation. Consider the input prompt:
The model generates the desired output:
By prepending instructions, we effectively condition the Transformer to generate tokens aligned with the specified task, enabling a wide range of applications such as translation, summarization, or question answering.
Simplicity and Power of Behavior Cloning
Although behavior cloning ignores exploration and focuses purely on supervised learning, it works remarkably well when:
- The dataset is large and diverse: High-quality trajectories provide ample information for the model to learn effective policies.
- The architecture is expressive: Transformers, with their attention mechanism, can capture complex dependencies and learn from long sequences.
The result is a model that, once trained, can generate high-quality sequences in response to appropriately crafted prompts, making methods like Decision Transformer and LLMs highly effective in offline settings.
Beyond Behavior Cloning: The Limitations and Potential
While behavior cloning is a powerful and efficient approach for learning from offline data, it comes with inherent limitations. To illustrate this, let’s consider the example of training a self-driving car:
The Self-Driving Car Example
If we want a self-driving car to drive as well as a skilled human driver, behavior cloning can be sufficient. By training the model on a large and high-quality offline dataset of human driving trajectories, the car can learn to mimic the decision-making patterns of experienced drivers. This approach aligns with the strengths of behavior cloning:
- Efficiency: The car learns without the need for real-world exploration.
- Safety: All training happens offline, without risking accidents during exploration.
However, if we aim to surpass human driving abilities, behavior cloning alone might not be enough. For instance, a fully autonomous system might discover strategies that humans would never consider, such as:
- Optimizing fuel efficiency through novel driving techniques.
- Maneuvering in complex traffic scenarios with split-second precision.
- Exploiting gaps in traffic laws for faster navigation.
Such capabilities can only be achieved through full reinforcement learning, where the agent learns not just from human data but also through exploration in a simulated or real-world environment.
Conclusion: Bridging the Gap Between Imitation and Innovation
Sequential decision-making is a challenging yet fascinating problem, with applications ranging from robotics to natural language processing. While behavior cloning offers a practical and efficient way to learn from offline data, it is inherently limited by the quality and scope of the training dataset. On the other hand, reinforcement learning, though computationally intensive, opens the door to surpassing human capabilities by enabling agents to explore and discover novel strategies.
Transformers, with their exceptional sequence modeling capabilities, have emerged as a powerful tool in this domain. Whether it’s driving a car, planning a trip, or generating human-like text, their ability to learn from and condition on sequences has revolutionized how we approach sequential decision-making.
Looking ahead, hybrid approaches that combine the strengths of behavior cloning and reinforcement learning hold immense promise, e.g., RLHF (reinforcement learning from human feedback). By starting with high-quality offline data and refining through exploration, we can build systems that not only imitate human behavior but also push the boundaries of what is possible. The journey is just beginning, and the potential for innovation is boundless.